docker

架构
重要概念
先弄清docker中的三个重要概念:镜像、容器、仓库
镜像是只读的,包含了基础操作系统文件和Linux运行的必要文件。镜像是静态的容器。文件系统中体现在所有镜像文件保存在diff文件夹下。
容器是加载镜像的sandbox
仓库是用于保存和分发镜像
文件系统
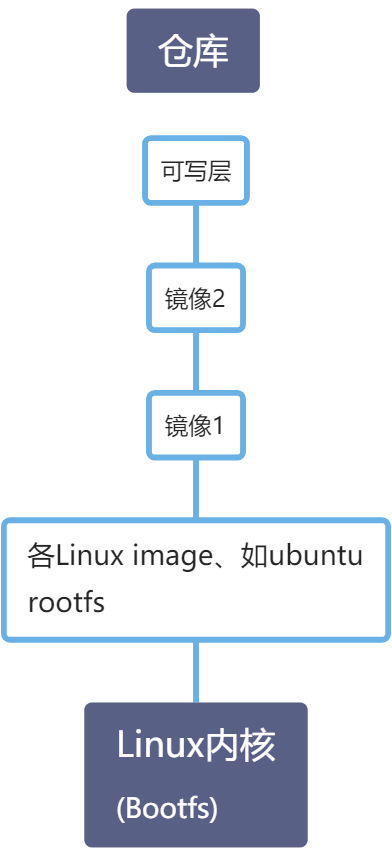 每个Linux的bootfs都是相同的,只有rootfs不同。
每个Linux的bootfs都是相同的,只有rootfs不同。
传统的Linux加载bootfs时会先将rootfs设为read-only,然后在系统自检之后将rootfs从read-only改为read-write,然后我们就可以在rootfs上进行写和读的操作了。
但Docker的镜像却不是这样,它在bootfs自检完毕之后并不会把rootfs的read-only改为read-write。而是利用union mount(UnionFS的一种挂载机制)将一个或多个read-only的rootfs加载到之前的read-only的rootfs层之上。在加载了这么多层的rootfs之后,仍然让它看起来只像是一个文件系统,在Docker的体系里把union mount的这些read-only的rootfs叫做Docker的镜像。但是,此时的每一层rootfs都是read-only的,我们此时还不能对其进行操作。当我们创建一个容器,也就是将Docker镜像进行实例化,系统会在一层或是多层read-only的rootfs之上分配一层空的read-write的rootfs。
Docker默认工作目录位于/var/lib/docker。
Image、container
docker最常见的用途就是从仓库上拉取别人已经制作好的各种镜像快速构建我们所需要的服务。这些服务可以是开发环境,也可以是已经在开发环境上进行过配置的完善服务套件,开箱即可提供服务。
举个例子,我们想搭建一个PHP博客,常会使用wordpress,wordpress是一个成熟的PHP框架,包含了完整的前台后台界面和解决方案,功能十分强大,但是也导致其所需要的依赖多、配置繁琐。我们如果不想浪费太多时间在安装PHP、apache和解决相互之间的链接问题,可以在docker仓库中寻找现成整站镜像,只需要一行命令
docker pull wordpress
就可以获得wordpress除了mysql数据库以外所需要的所有准备,给内容创作留更多的精力吧!
获取镜像之后我们需要将镜像化为实例才能运行起来:
docker run
- -d 允许在后台运行
- -p 指定端口映射 如: -p 8080:80 就是将容器内的80端口映射到主机的8080端口
案例:使用docker搭建静态网站
**
我的主机已经启用了 WSL2,相比于WSL,WSL2包含完整的Linux内核,是一个完整的虚拟机,天然提供了docker的host环境。所以在Windows上使用WSL2作为docker的主机环境是完全可行且被推荐的,甚至可以投入生产环境。
要实现以上设想,首先需要启用hyper-v服务,安装wsl2的升级package。然后安装docker desktop
注意,hyper-v是个比较麻烦的东西,开启后很难干净地删除,且可能与其他虚拟机相冲突;所以学习docker还是建议在虚拟机中完成
使用docker version 验证是否安装成功:
出现了版本信息,安装成功!
**
我们现在只有docker引擎本体,要使用成千上万的docker服务还需要有镜像(image),并将镜像实例化为容器(container)
**
从docker 仓库(repository)拉取镜像的命令是
docker pull nginx
注意保证网络环境的稳定。服务器位于国外且对大陆网络不友好。
pull成功后用docker images看一下有没有出现在镜像列表中:
**
docker run -d -p 127.0.0.1:8080:80 --rm --name mynginx --volume /root/html:/usr/share/nginx/html nginx
–name : 命名容器
-v : 指定挂载在哪个目录 用 : 分割宿主机目录和docker容器内部目录
-d 保持容器在后台运行
这样,我们的nginx实例容器就创建好了,这也是docker魅力所在:
将人的精力放在内容的创作上,而不是浪费在环境的搭建、软件的配置上。
开箱即用,用完即走
此时打开浏览器,即可访问到刚刚创建的网页
Docker 取证常用命令
docker inspect [name|id]
获取容器/镜像的元数据信息
例如容器、镜像的创建时间
疑问:docker在linux中创建的容器所使用到的文件会不会和正常安装的软件目录路径相同
**